Building a Kubernetes cluster
Published on Jun 08
Note: This post is continuing on my previous post “Building a Kubernetes-ready Fedora CoreOS image”
In the past few years, Kubernetes has become more and more of an industry-standard. It has revolutionized the way we (DevOps engineers, developers, sysadmins,..) deploy, manage and scale applications. Kubernetes has quickly become the de facto standard for container management in the industry. It offers a robust and scalable solution for automating the deployment, scaling and operation of application across a cluster of hosts. With its rich set of features, including autoscaling, load balancing and self-healing, Kubernetes empowers developers and sysadmins to build and manage resilient cloud-native applications. In this post, I’d like to go through the basic steps needed to set up a Kubernetes cluster.
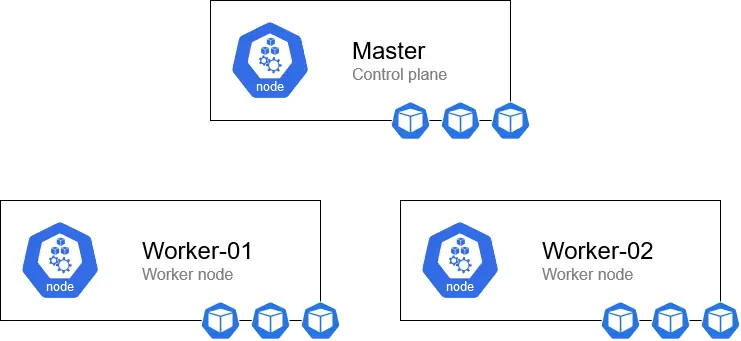 |
|---|
| A rough overview of what we’ll be building in this post. |
Master
A Kubernetes needs one (or more) master node(s). These nodes play a crucial role in managing and controlling the cluster. They are responsible for orchestrating and coordinating the overall operation of the cluster. A master node acts as the control plane, scheduling applications, monitoring their health and maintaining desired state. It manages the cluster’s shared resources and ensures that containers are deployed to the appropriate worker nodes.
Prerequisites
Before we can actually initialize the cluster, we need to prepare our machine. First, we’ll need to set a hostname (that way we can easily identify the node). After that, you can install the kubectl, kubelet, kubeadm and cri-o packages.
- Kubectl: a CLI tool used to interact with Kubernetes clusters. Used to communicate with the Kubernetes API server.
- Kubelet: essential component of a Kubernetes responsible. Responsible for managing and supervising containers on Kubernetes nodes. Acts as a bridge between the control plane and the containers.
- Kubeadm: a CLI tool used designed to simplify the process of setting up and initializing a Kubernetes cluster.
- CRI-O: open-source implementation of the Container Runtime Interface (CRI) specifically designed for Kubernetes. It’s lightweight and optimized for Kubernetes, what’s not to like?
Once these tools are installed, it’s best to reboot your machine (there should be a message telling you to reboot anyway). Once the machine has rebooted, you can start both the kubelet and the crio systemd services (and enable them on boot).
sudo hostnamectl set-hostname master
sudo rpm-ostree install kubectl kubelet kubeadm cri-o
sudo systemctl reboot
sudo systemctl enable kubelet --now
sudo systemctl enable crio --now
Cluster initialization
Now that we’ve installed all the necessary components, it’s time to get to the fun stuff, initializing our cluster! To do this, we’ll create a YAML file defining our cluster configuration.
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: v1.27.2
controllerManager:
extraArgs:
flex-volume-plugin-dir: "/etc/kubernetes/kubelet-plugins/volume/exec"
networking:
podSubnet: 10.244.0.0/16
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
bootstrapTokens:
- token: "suuw0o.w5h0w4wv6po1lcwb" # Insert token from `kubeadm token generate` command
description: "kubeadm bootstrap token"
ttl: "24h"
So, what do we have here? Well, to quickly go through it:
Cluster configuration
These are settings that get used when running the cluster.
- kubernetesVersion: this is pretty self-explanatory, it defines the version of Kubernetes we want to use. At the time of writing this post, 1.27.2 is the latest version, but you can always check if there are newer version available here.
- controllerManager: in this part we can define extra arguments which are passed to the control plane when setting things up.
- flex-volume-plugin-dir: this sets the directory where the Flex Volume data gets stored. This is something very specific we need to configure when using Fedora CoreOS.
- networking: yeah, this configures networking when setting up the cluster.
- podSubnet: as the name might suggest, this sets the subnet which will be used for the pods. I keep this at 10.244.0.0/16 as this is the default for Flannel but more on that later.
Init configuration
These are settings that get used when initializing the cluster.
- bootstrapTokens: in here, we can define a list of bootstrap tokens. These are tokens that we can use to join new nodes to the cluster. You can generate a bootstrap token by executing the
kubeadm token generatecommand.
Now that we’ve got our configuration file on point, it’s time to initialize the cluster using it. This is pretty straightforward, we can just execute the following command and wait for it to finish.
kubeadm init --config kubeadm-config.yml
Once this has finished, you should be greeted by a “success” message. This message includes a join command, let’s copy that and put it aside somewhere (in a notepad or so). This message also includes a set of commands which copy the Kubectl configuration file from its original location to the “.kube” directory in your home directory:
mkdir ~/.kube
sudo cp /etc/kubernetes/admin.conf ~/.kube/config
chown $(id -u):$(id -g) ~/.kube/config
Once you’ve executed those commands, you should be able to execute kubectl get nodes and see your master node in your brand-new Kubernetes cluster!
Installing a networking solution
Kubernetes clusters need networking. Not only so the nodes can communicate between each other, but pods also need to communicate. Even when they’re on different nodes. That’s where a networking solution comes in, you’ve got plenty of options to choose from. You’ve got Calico, Weave, Cilium, Flannel and many more. I personally prefer Flannel as it has all the feature a simple cluster needs, while also being lightweight.
Flannel’s installation is pretty easy, you can apply the latest version of the Kubernetes manifest and all the resources should come online.
kubectl apply -f https://github.com/flannel-io/flannel/releases/download/v0.22.0/kube-flannel.yml
Verifying that Flannel has successfully been deployed can be done using the kubectl get pods --namespace kube-flannel command. If there are no pods where the status is not “Running”, it has successfully been deployed. However, if there are issues, the best way to troubleshoot is to check the info on their GitHub repo!
Workers
We’ve got our master node set up, that’s the first step. Next is the worker nodes. These nodes will be doing the heavy lifting as they are responsible for running the containers that make up the applications and services deployed within the cluster. Worker nodes are managed by the Kubernetes control plane and work in conjunction with the master nodes to ensure the proper functioning of the cluster.
When you’re deploying more and more applications to a cluster and you’re noticing that the resources of your nodes are fully used, these worker nodes are the ones you’ll want to scale (horizontally or vertically).
The commands in the “Prerequisites” and the “Joining the cluster” should be executed on each worker node (2 in our case).
Prerequisites
The prerequisites for a worker node are mostly the same as those for a master node. I won’t go into too much detail here because of that. The only difference is that we don’t install kubectl on the worker nodes as we won’t be managing the cluster from these machines. Also, don’t forget to change the hostname, these are important for identifying which node is which.
sudo hostnamectl set-hostname worker-xx # Replace xx with the number of the node (01, 02, 03,..)
sudo rpm-ostree install kubelet kubeadm cri-o
sudo systemctl reboot
sudo systemctl enable kubelet --now
sudo systemctl enable crio --now
Joining the cluster
So, we’ve got our worker nodes prepared, it’s time to let them join the party. Joining a Kubernetes cluster is fairly easy. Using a single command, a worker node can join the cluster and be ready to receive workloads.
Remember that command we copied to a notepad after we initialized our cluster? It’s time to get that back and execute it! It should look something like this:
Note: if you forgot to copy the command and can’t find it back in your terminal, don’t worry! You can retrieve the command by executing
kubeadm token create --print-join-commandon your master node.
kubeadm join \
--token "suuw0o.w5h0w4wv6po1lcwb" \
--discovery-token-ca-cert-hash sha256:47e4ca6b6197e46f4953ff462c000523a4ca4fe3a2bd4b1a1deaa2934cd61a55 \
master_ip:6443 ## Replace master_ip with the IP address of the master
After executing (with the correct token and master_ip) the above command, you should see the worker node being joined to the cluster.
Verifying our installation
If everything went to plan, you should now have a cluster with 3 nodes. One of these nodes should have the “control-plane” role and the other two without a specific role.
[vdeborger@node-01 ~]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-01 Ready control-plane 1h7m v1.27.2
node-02 Ready <none> 1h6m v1.27.2
node-03 Ready <none> 1h6m v1.27.2
You should also see about 12 pods running in your cluster. 3 of which are the Flannel pods, the others are all components necessary to run the cluster.
[vdeborger@node-01 ~]$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-bhzhq 1/1 Running 0 1h47m
kube-flannel kube-flannel-ds-cvnds 1/1 Running 0 1h48m
kube-flannel kube-flannel-ds-dnrnp 1/1 Running 0 1h47m
kube-system coredns-5d78c9869d-dnrr9 1/1 Running 0 1h47m
kube-system coredns-5d78c9869d-slcc5 1/1 Running 0 1h47m
kube-system etcd-node-01 1/1 Running 0 1h48m
kube-system kube-apiserver-node-01 1/1 Running 0 1h47m
kube-system kube-controller-manager-node-01 1/1 Running 0 1h47m
kube-system kube-proxy-g5rw4 1/1 Running 0 1h47m
kube-system kube-proxy-ml9z9 1/1 Running 0 1h48m
kube-system kube-proxy-wjnz5 1/1 Running 0 1h47m
kube-system kube-scheduler-node-01 1/1 Running 0 1h47m
If everything looks good, you’ve successfully set up a Kubernetes cluster! 🥳
What’s next?
That’s entirely up to you! You can run whatever your heart desires. Do you want to run your Minecraft server on Kubernetes? That’s possible! Want to get started with DevOps and run your very own Jenkins instance? That too, is possible!
However, if you’re new to Kubernetes, it’s best to start small. By first learning some of the basics, you’ll be better in debugging issues when you’re running more advanced applications. I’ve listed some of my personal recommendations to get started with Kubernetes below, but there’s a lot of information you can find on the internet.
- Deploy an NGINX pod inside your cluster
- Change your Kubernetes manifest so you’re no longer using a pod but a deployment
- Scale your NGINX pod to 3 and see how Kubernetes automatically distributes the workload
- Expose the NGINX pod using a service and access the NGINX index page